Projects
If you find something helpful here, please attribute it. If something catches your eye and/or you would like to collaborate, please reach out.
The 1818 Select Committee on the Education of the Lower Orders, chaired by Henry Brougham, sent forms to parish clergy throughout England and Wales soliciting information about the provision of schools in their parishes. In their report to parliament, the committee summarized these findings at the county level, and these summaries have been more commonly employed by historians. However, while the parish-level returns were also published at the same time, they have not to my knowledge been transcribed and digitized for use by historians.
There are many possible reasons for this. In the first place, transcribing data about approximately 15,000 parishes is far more labour-intensive than doing the same for the 52 counties of England and Wales. The returns are also of relatively limited usefulness, as they are not believed to accurately reflect the extent of fee-paying school provision in built-up areas. Nonetheless, these returns provide the earliest evidence about the distribution of Sunday schools, and for this purpose they can be expected to be reasonably accurate. Unlike the more ephemeral dame and common schools that met in private homes, Sunday schools were public-facing institutions that hosted cultural events and social clubs and would have been well-known to the clergy who completed the returns.
My own interest in Sunday Schools arises from my argument that commonly-used measures of human capital, e.g., day school attendance and signature rates on marriage documents, miss the greater numbers of children who attended schools that taught reading but not writing, primary among which were Sunday schools. This interest spurred me to attempt to create a more detailed database of the early Sunday school returns.
First, I decided it would be far too time-consuming to transcribe the names and data of approximately 15,000 parishes in England and Wales and opted to use various Python packages suited to
automatically reading digital images. I proceeded in three stages. First, using cv2 for computer vision, I wrote an algorithm that would extract only those images from the tables in
which I was interested. Then I used pytesseract for optical character recognition to "read in" the extracted images to a digital format. Finally, I used fuzzywuzzy for
fuzzy matching to join up the extracted parish names (possibly containing errors) to a set of standardized placename identifiers produced by the
Cambridge Population Group for their GIS files. I will outline each step in detail.
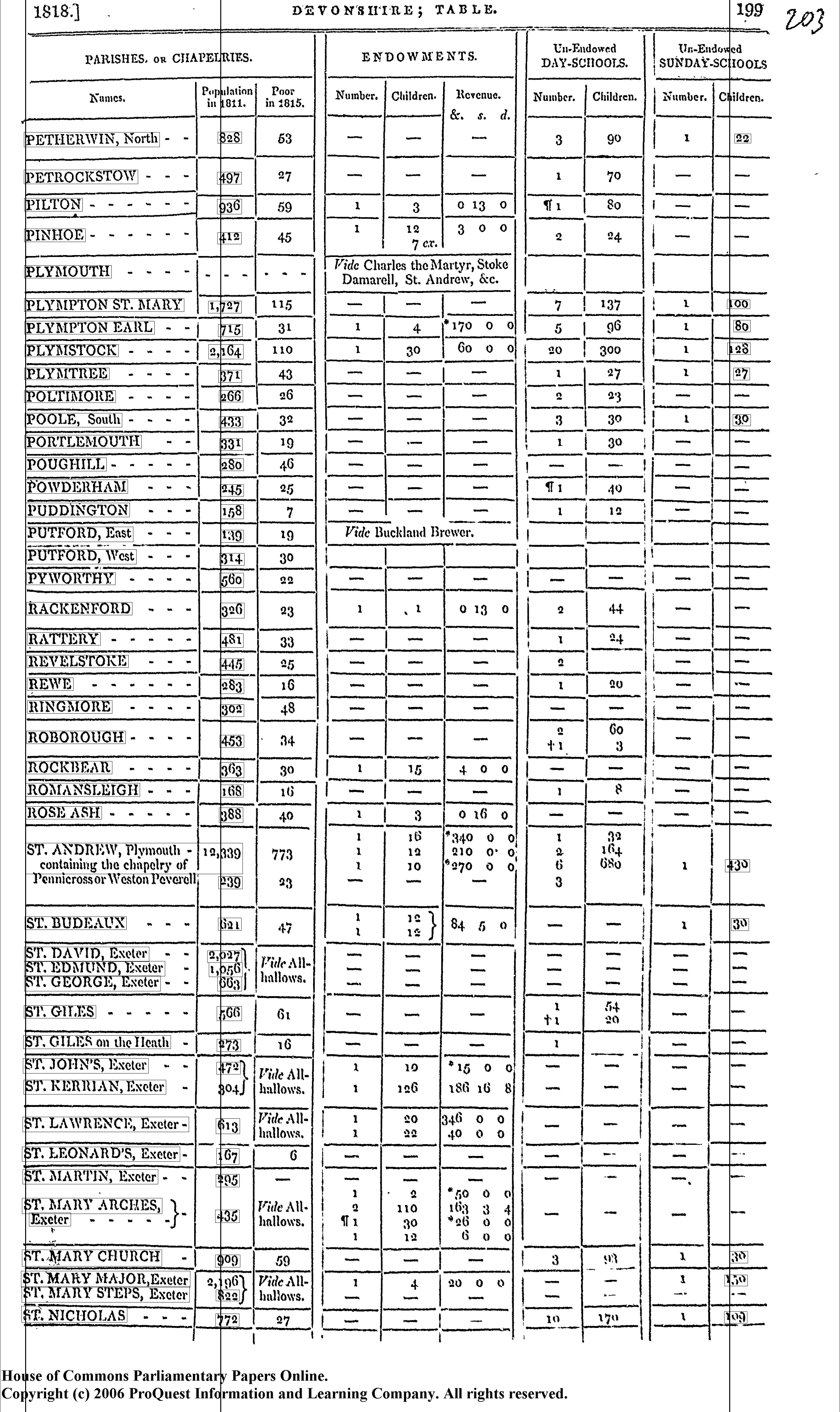
I began with a set of images like the one below --- a copy of a page from the report on Devonshire. It is organized into a tabular format, and I am primarily interested in the final column containing information about the number of children attending unendowed Sunday schools in each parish. (There were no endowed Sunday schools enumerated in the report.) However, I will also need to know the parish or chapelry name, and I will also extract the population figure to enable the calculation of per capita enrolment.
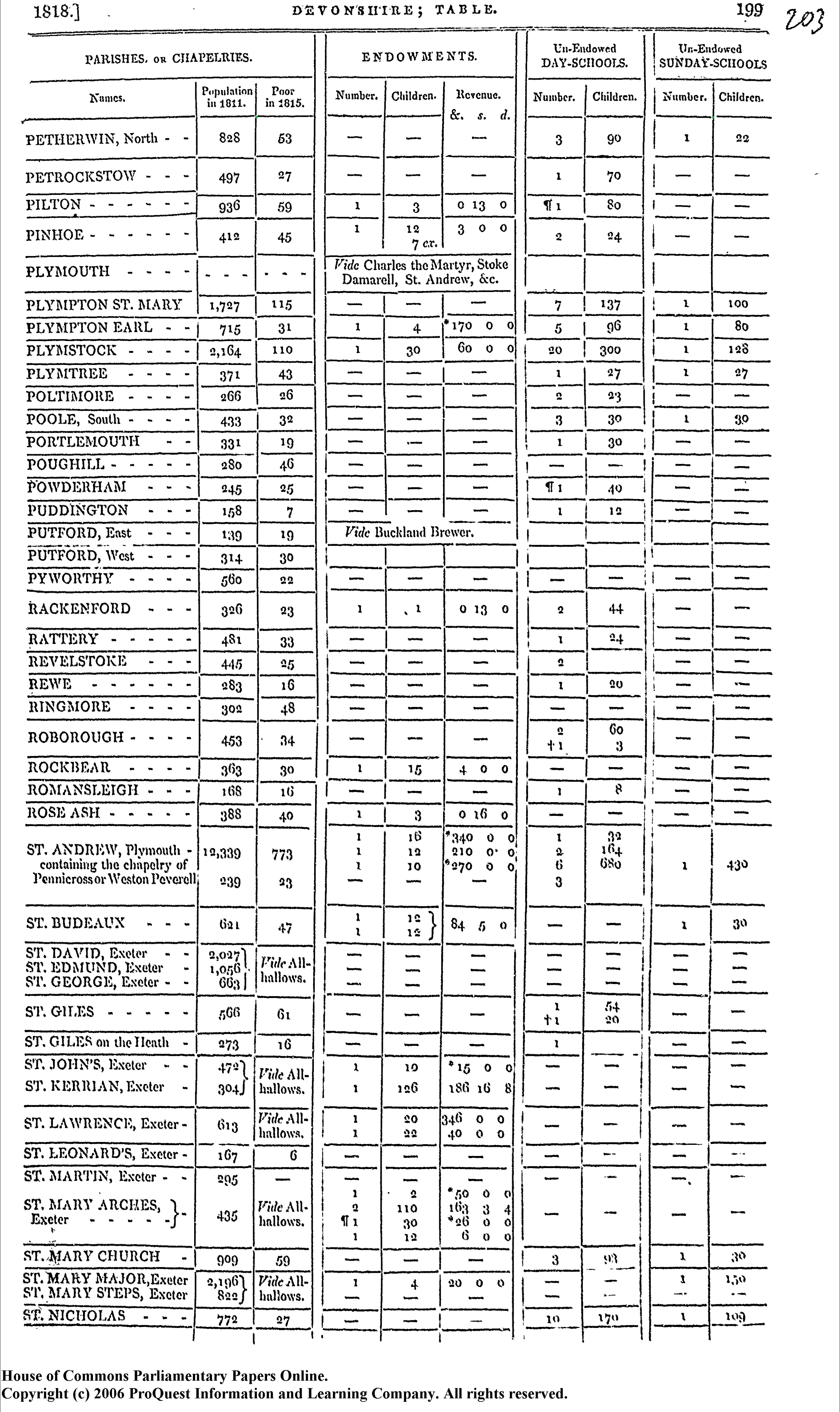
To improve accuracy, it is helpful to take various pre-processing steps. The simplest of these is to mark the location of the columns I am interested in with a green point to enable the algorithm to find
them later, given that these old scans are not all aligned and may vary from image to image. I also apply a kernel filter to "stretch out" the text horizontally and compress it vertically. The cv2 package works by drawing
countour lines around all continuous foreground images, and I found through trial and error that this kernel more consistently picked up the letters from the background despite printing
imperfections present in the original document. Finally, after identifying all foreground images, I only retain those that belong to the columns in which I am interested and draw bounding boxes,
which are simpler to work with, around each foreground image. The code for these steps (commented throughout) is as follows:
import cv2 #import the library
import numpy as np
#file = MUST DEFINE OWN FILEPATH TO IMAGE
im1 = cv2.imread(file, 0) #load a greyscale version of the image
im = cv2.imread(file) #load a colour version of the image
ret,thresh_value = cv2.threshold(im1,180,255,cv2.THRESH_BINARY_INV) #converts greyscale values to black if below the threshold and white otherwise
# apply the kernel to dilate the image horizontally and erode the image vertically
vert_kernel = np.ones((2,1),np.uint8)
hor_kernel = np.ones((1,5),np.uint8)
dilated_value = cv2.dilate(thresh_value,hor_kernel,iterations = 3)
eroded_value = cv2.erode(dilated_value,vert_kernel,iterations = 2)
# identify the coordinates of the green column markers
green_markers = []
lower_bound = np.array([50,20,20]) # define the lower bound for green in HSV format
upper_bound = np.array([100,255,255]) # define the upper bound for green
hsv = cv2.cvtColor(im,cv2.COLOR_BGR2HSV) # convert image to HSV format
colour_mask = cv2.inRange(hsv,lower_bound,upper_bound) # pick out green parts of image
contours, hierarchy = cv2.findContours(colour_mask,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) # draw contours around green parts
for cnt in contours: # get a list of x and y coordinates of green parts of image and sort by x coordinate
x,y,w,h = cv2.boundingRect(cnt)
green_markers.append((x,y))
green_markers.sort(key=lambda x: x[0])
# find the contours of the greyscale image
contours, hierarchy = cv2.findContours(eroded_value,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
coordinates = []
for cnt in contours:
x,y,w,h = cv2.boundingRect(cnt) # choose only those images that fall in the correct part of the page relative to the green markers
if page_index == 0: # the formatting is slightly different for the first page of the summary tables for a county, so this variable accounts for which page is being read
if (x < green_markers[0][0] or x > green_markers[-1][0]) and y > green_markers[0][1] and y < 4200 and h > 18 and h < 60 and w > 20 and w < 520:
coordinates.append([x,y,w,h])
elif page_index == len(files)-1: ## different format for last page in county summary table series
if (x < green_markers[0][0] or x > green_markers[-1][0]) and y > green_markers[0][1] and y < green_markers[-1][1] and h > 18 and h < 60 and w > 20 and w < 520:
coordinates.append([x,y,w,h])
else: # every other middle page follows the same format
if (x < green_markers[0][0] or x > green_markers[-1][0]) and y > green_markers[0][1] and y < 4200 and h > 18 and h < 60 and w > 20 and w < 520:
coordinates.append([x,y,w,h])
This algorithm leaves me with the x, y, w(idth), and h(eight) values of the bounding boxes
surrounding all of the foreground images picked up after applying threshold, (horizontal) dilation and (vertical) erosion filters and which fall within the part
of the page given to the placename, population and Sunday school columns. As many of these images will be single letters (if space between characters remains after
applying the filters), while others will be groups of letters or whole words, further code attempts to group images into more standard word-forms. To do so, I define the following function:
# if the two boxes overlap, returns the enlarged bounding box
def overlap(source, target, xmargin):
# unpack points
x1,y1,w1,h1 = source
x2,y2,w2,h2 = target
# checks and returns new bounding box
if (x1 - xmargin >= x2 + xmargin + w2 or x2 - xmargin >= x1 + xmargin + w1):
return x1,y1,w1,h1, False # i.e. false, return the old box
if (y1 - 2 >= y2 + h2 or y2 - 2 >= y1 + h1):
return x1,y1,w1,h1, False # i.e. false, return the old box
return min(x1,x2),min(y1,y2),max(x1+w1,x2+w2)-min(x1,x2),max(y1+h1,y2+h2)-min(y1,y2), True # return the bounding box of overlapping boxes
Given two bounding boxes, this function will return a new bounding box surrounding both input boxes, and it takes a horizontal margin that expands the potential overlap area horizontally by the margin. I then iterate through all the bounding boxes to find any overlaps, removing the old boxes where an overlapping box is found. After this step, I expand final bounding boxes surrounding each item by a few pixels, as I found this improved the accuracy of OCR in later steps.
for _iter in range(3):
for i in coordinates:
x,y,w,h = i
for j in coordinates:
if i != j:
x,y,w,h, match = overlap([x,y,w,h],j,25)
if match:
coordinates.remove(j)
coordinates.remove(i)
coordinates.append([x,y,w,h])
# expand final width of bounding boxes to improve OCR
for x in coordinates:
x[1] -= 3
x[3] += 5
x_values.append(x[0])
I was therefore left with bounding boxes surrounding the items in the columns in which I was interested from the original table, but I needed some way to identify the location
of the columns on the x-axis. Using the python package scipy, I found the three peaks (local optima) of the kernal density of the distribution of x,
which corresponded to the location of the three columns. Admittedly, this step is a little bit more computationally demanding than it has to be because I ultimately settled on using green markers
to identify the columns, but this code is a holdover from an earlier version of the algorithm that did not use green markers. I did not mind having slow code, and this method worked fine,
so I left it in.
from scipy.signal import find_peaks
from scipy.stats import gaussian_kde
x_values = []
kde = gaussian_kde(x_values, bw_method=0.2)
x_set = np.linspace(0,im.shape[1],100)
columns, _ = find_peaks(kde.evaluate(x_set), distance=10)
parish_loc = round(x_set[columns[0]])
population_loc = round(x_set[columns[1]])
sunday_loc = round(x_set[columns[-1]])
At this point, I had bounding boxes around the items in which I was interested and enough information to sort them into tabular form. The bounding boxes and column locations are overlaid over the original image below to illustrate.
Clearly, this process is not perfect. Pennicross in St. Andrew, Plymouth, for instance, has been missed entirely. In general, automated methods will sacrifice accuracy for speed, no matter how carefully they are designed.
That said, the algorithm has not yet been completely described, and it is premature to begin such assessments. With information on the location of each column, it remains to sort every item into its proper row. I defined each row to correspond with exactly one item from the first column. At this stage, however, I found it simpler to convert the images into text while sorting them into rows and columns rather than doing each step concurrently, so it is necessary, at this point, to explain the OCR process briefly.
Optical Character Recognition (OCR) converts images of text into a machine-readable string format. The latest version of Tesseract (an open source OCR engine) uses a neural network algorithm behind the scenes to find the most likely character, taking various inputs from users to direct the engine to more accurately identify text. For example, while I found that the default language settings did a reasonably good job of reading the placenames from the table, I was able to improve its accuracy by specifying which "page-segmentation mode" to use in different scenarios. For ordinary placenames falling on one single line, the following line of code tells Tesseract to interpret the image as a raw line:
pytesseract.image_to_string(sub_img, config="--psm 13 --oem 3")
In contrast, the following line of code tells Tesseract to interpret the image as a single-column block of text, useful for instance where the placename extends over multiple lines like Plymouth, St. Andrew:
pytesseract.image_to_string(sub_img, config="--psm 4 --oem 3")
Using this powerful tool, I began putting together a dataset with all of the relevant information contained in the table. First,
I iterated through items in the first column, which I identified by comparing their distance to the previously identified x
coordinate of each column, and picked out a subsection of the original image corresponding to their bounding box. I passed this sub-image to
the OCR engine, which turned it into text. If the bounding box was large enough to suggest that the placename covered multiple lines of text,
I instructed the OCR engine to change its psm to a multi-line mode. Finally, I also passed the y coordinate of each item
to the dataset so that it could be referred to in later steps linking other columns to the correct row. This process is translated into code below.
import pytesseract
data = {} # define a blank dictionary in which to put data
row_index = 0 # start the indexing function at 0
coordinates.sort(key=lambda a:a[1]) # sort the items according to their y values
for i in coordinates:
if abs(i[0]-parish_loc) < 50: # the item is in the parish column
sub_img = im[i[1]:i[1]+i[3],i[0]:i[0]+i[2]] # extract a sub image from the original containing only the text based on coordinates
if i[3] > 70: # if height of the image extends over two lines change the psm
data[str(page_index)+"-"+str(row_index)] = [i[1], pytesseract.image_to_string(sub_img, config="--psm 4 --oem 3")]
else:
data[str(page_index)+"-"+str(row_index)] = [i[1], pytesseract.image_to_string(sub_img, config="--psm 13 --oem 3")]
row_index += 1 #increment the index function
As mentioned, this did a reasonably good job of reading the placenames, at least to a standard that the fuzzy matching algorithm was able to recognize in later steps. It was
a very different story for the numbers in the population and Sunday School columns. While the majority of numbers were read accurately, the default language engine would drop entire numbers or
read them as letters instead --- with concerning regularity. As it is very important that these numbers be as accurate as possible, I opted to make use of Tesseract's included language training system. This is a form of supervised
machine learning that allows users to train the OCR engine on a custom set of images, thereby vastly improving its accuracy for specific applications. I also instructed Tesseract that it would
only be reading numeric characters in these columns and set its page-segmentation mode to look for a single word. The line of code refering to my custom-trained language (parl for Parliamentary
Papers) and restricting the possible characters to numbers is:
pytesseract.image_to_string(sub_img, lang='parl', config='--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789')
Before being able to append the population and Sunday scholar figures to their proper rows, however, I needed to define a function that returns from an input list of bounding box coordinates the nearest
y value to an input value:
def find_nearest_y(coordinates, value, sort=True):
if sort:
coordinates.sort(key=lambda a:a[1])
#list needs to be sorted ascending by y first
previous_diff = 100000 # arbitrary large number to begin with
for i, coord in enumerate(coordinates):
diff = abs(value-coord[1])
if (diff - previous_diff) > 0: # if the next difference in the sequence is larger than the last one, then the last difference was the minimum
return i-1
else:
previous_diff = diff
continue
if not coordinates: ## i.e. if list is empty
return None
else: # if nothing else, it is the last item in the sequence
return i
Using this function, I then assigned values from the population column to the one row they were nearest to on the y axis, as long as the distance between the population value and the name did not exceed some threshold. This was to attempt to avoid the possibility that a population value be assigned to an incorrect parish if the actual parish, for instance, had not been identified by the computer vision algorithm. I also ensure that each population value is uniquely assigned to a single row. This process is translated into code below.
pop_column = [] # define the blank list for the population values
for x in coordinates:
if abs(x[0]-population_loc) < 100: # add items to the list if they are in the correct column
pop_column.append(x)
for row_index in range(len(data)):
closest = find_nearest_y(pop_column, data[str(page_index)+"-"+str(row_index)][0], sort=False)
if closest != None: # if the list is not empty
distance_to_nearest = pop_column[closest][1]-data[str(page_index)+"-"+str(row_index)][0]
if distance_to_nearest > -20 and distance_to_nearest < 40: # if nearest row is near enough
sub_img = im[pop_column[closest][1]:pop_column[closest][1]+pop_column[closest][3],pop_column[closest][0]:pop_column[closest][0]+pop_column[closest][2]] # extract the sub-image
data[str(page_index)+"-"+str(row_index)].append(pytesseract.image_to_string(sub_img, lang='parl', config='--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789')) # append OCR
del pop_column[closest] # remove that population value so that it is uniquely assigned to a row
else:
data[str(page_index)+"-"+str(row_index)].append("n/a")
else:
data[str(page_index)+"-"+str(row_index)].append("n/a")
I then performed an analogous process for the Sunday school column.
sunday_column = []
for x in coordinates:
if abs(x[0]-sunday_loc) < 100:
sunday_column.append(x)
for row_index in range(len(data)):
closest = find_nearest_y(sunday_column, data[str(page_index)+"-"+str(row_index)][0], sort=False)
if closest != None:
distance_to_nearest = sunday_column[closest][1]-data[str(page_index)+"-"+str(row_index)][0]
if distance_to_nearest > -25 and distance_to_nearest < 55:
sub_img = im[sunday_column[closest][1]:sunday_column[closest][1]+sunday_column[closest][3],sunday_column[closest][0]:sunday_column[closest][0]+sunday_column[closest][2]]
data[str(page_index)+"-"+str(row_index)].append(pytesseract.image_to_string(sub_img, lang='parl', config='--psm 8 --oem 3 -c tessedit_char_whitelist=0123456789'))
del sunday_column[closest]
else:
data[str(page_index)+"-"+str(row_index)].append("0")
else:
data[str(page_index)+"-"+str(row_index)].append("0")
At this point, the processed data looked something like the table below. Clearly, it is not perfect, but the data is in a workable state. There are many minor errors in the transcription of characters in the placenames, and a few of the numbers are incorrect. Another process called fuzzy matching is able to find the most likely match from a list of possible contenders, and it is this process that I employ to clean up the placenames and match the data to existing GIS maps of England and Wales.
| PETHERWIN, North | ||
| PETROCKSTOW | 497 | 0 |
| PpILTON | 936 | 0 |
| PINHOLE | 412 | 0 |
| PLYMOUTH | n/a | 0 |
| PLYMPTON ST. MARY | 1727 | 100 |
| PLYMPTON EARL | 715 | 80 |
| PLYMSTOCK | 2164 | 1923 |
| PLYMTRELS | 371 | 27 |
| POLTINORE | 266 | 0 |
| POOLE, South | 433 | 30 |
| PORTLEMOUTIL | 331 | 0 |
| POUGHILL | 280 | 0 |
| POWDERHAM | 245 | 0 |
| PUDDINGTON | 158 | 0 |
| PUTFORD, East | 139 | 0 |
| PUTFORD, West | 314 | 0 |
| PYWORTHY | 560 | 0 |
| RACKENFORD | 326 | 0 |
| RATLERY | 45 | 0 |
| REVELSTOKE | 445 | 0 |
| REWE | 283 | 0 |
| RINGMORE | 302 | 0 |
| ROBOROUGH | 453 | 0 |
| ROCKBEAR | 363 | 0 |
| ROMANSLEIGH | 168 | 0 |
| ROSE ASH | 988 | 0 |
| ST. ANDREW, Plymouth - | 19,939containing the chapelry of | | n/a | 439 |
| ST, BUDBAUX | 621 | 30 |
| ST. DAVID, Exeter | 2027 | 0 |
| ST. EDMUND, Exeter | 1056 | 0 |
| YLT. GEORGE, Exeter | 663 | 0 |
| ST. GILES | 566 | 0 |
| ST. GILES on the Heath | 273 | 0 |
| ST, JOHN’S, Ixeter | 472 | 0 |
| ST. RERRIAN, Excter | n/a | 0 |
| ST. LAWRENCE, Exeter - | 613 | 0 |
| ST. LEONARD’S, Exeter | 167 | 0 |
| ST. MARTIN, Exeter | 205 | 0 |
| ST, MARY ARCHES, | 435 | 0 |
| Exeter | n/a | 0 |
| ST. MARY CHURCH | 909 | 30 |
| ST. MARY MAJOR,Exeter | n/a | 150 |
| ST, MARY STEPS, Exeter | 8240 | 0 |
| SE NICHOLAS | 272 | 199 |
More to come....
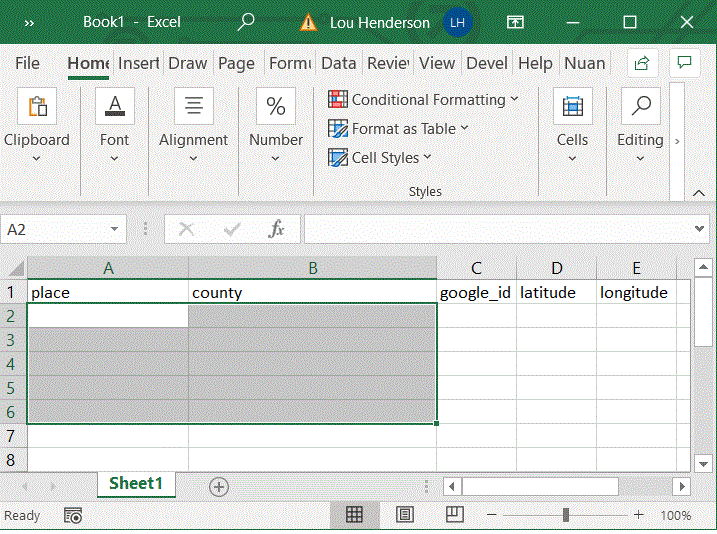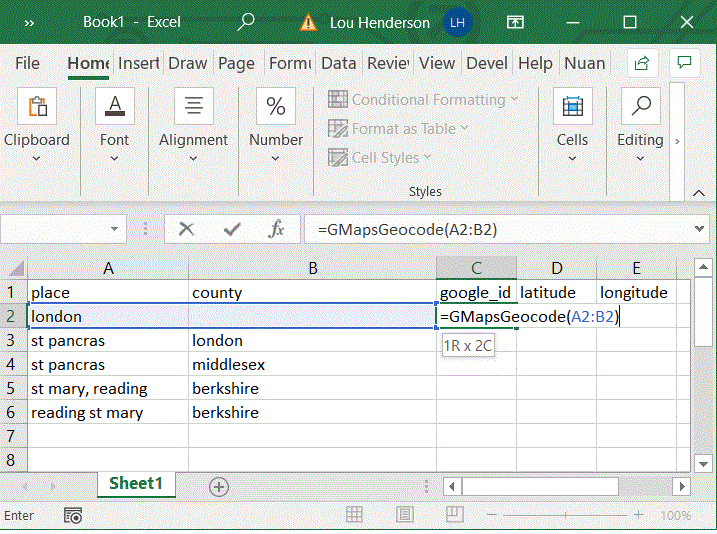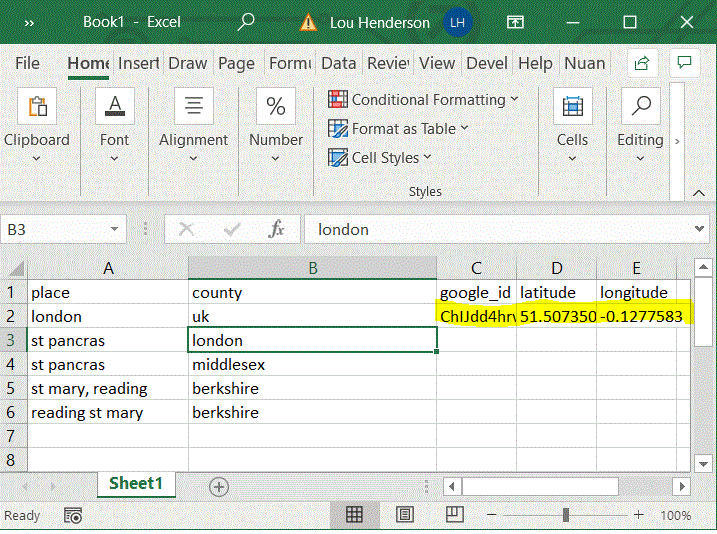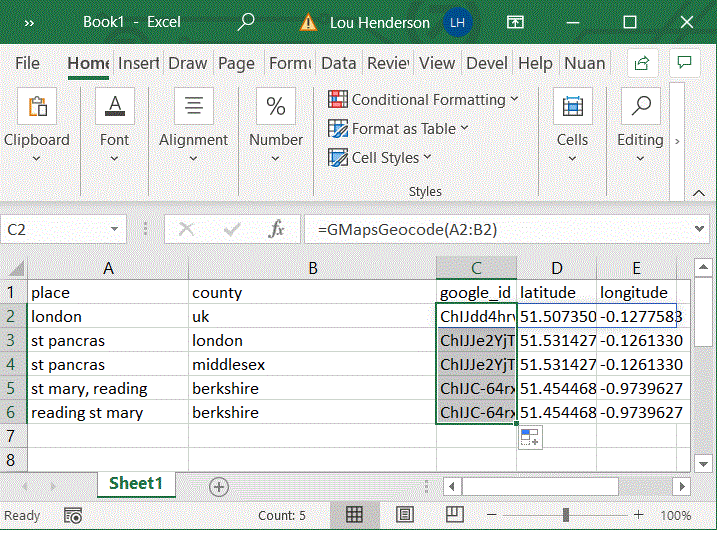
This add-in creates an Excel function ("GMapsGeocode") that lets you automatically populate your spreadsheet with data pulled from the Google Places API. Select a cell or range of cells containing placename information. The function fills three columns with a unique place id, longitude, and latitude. It will only return one result, determined the most "significant" per Google. It is useful for rapidly matching non-standardized historical placenames, such as a parish, across datasets, as there will often be a modern church or other significant building with the same name at the same site.
You will need your own Google API key. Excel will prompt you for this when you first use the add-in. This is because there are restrictions on the number of free data requests Google will provide. A single user, however, should not come up against these limits unless they regularly work with very large datasets.
Details of Google API are here.
To use, simply download the file and open it from the Excel document you wish to use the add-in on. Allow macros, and follow the steps in the image below. The output of the function requires three empty columns, and the input can take one or more cells, as long as they are adjacent to one another and can be input as a range.
Note: if working with very large datasets, it is a good idea to use the functiopytesseract.image_to_string(sub_img, config="--psm 13 --oem 3")n on a limited number of entries (~2000) at a time. The function may use too much memory and freeze Excel otherwise. To save data and processing power, it helps to only call the function on unique values of a placename and then assign the coordinates to all other matching entries using Excel's INDEX and MATCH or VLOOKUP.